使用データ(注2)
上で紹介した近藤・畠中の研究を逆から解釈すると、3年生4月時点で除退となる学生の特徴は入学直後から顕在化するということである。この視点は極めて重要で、彼らへの対策などを適正かつ早期に講じれば、除退防止の有効な手段になるということである。まさに「鉄は熱いうちに打て」である。
この視点でもう1つ重要なことは、除退予備軍の学習態度が講義などへの出席状況や初年次段階の成績で把握されるということである。しかし、前述(関連記事:『「文字は口以上に物を言う」現役教授が提案、新たな学力指針!』)でも指摘したように、講義に休みがちになる段階で除退阻止に向けて動くのはタイミングが悪く、成績が明らかになってから動いても手遅れである。
大学という場所から逃げ出し始めた学生は追いかけるほど逃げ足が速くなるからである。現場にとって重要なことは、逃げ出す前の段階で発するであろうシグナルが何かということを見出すことである。
本章では、シートに書かれた文字情報が重要なシグナルとなるという仮説を立て、そのサンプルとして導入講義受講者の文字情報と除退との関連について検証していきたい。
そのために、ここでは使用データについて解説する。
サンプルは前述(関連記事:『【統計分析の手本】大学教授が行った「授業アンケート」は…』)と同じもの、すなわち2013~7年度にかけて開講された導入講義の受講登録者489名(男子420名〔うち5名は該当の講義期間中に除退〕、女子69名)である。基礎データとして、登録者の2回生春学期末から卒業時までの学籍状況、導入講義の欠席回数(シート未提出を欠席と判断)および成績を用いた。
学籍状況については2020年度春学期末時点で在籍していれば0、2回生春学期末時点で除退すれば1、以下、2回生秋学期末で2、3回生春学期末で3、秋学期末で4、4回生春学期末で5、秋学期末で6、5回生以上で7とするカテゴリー変数である。
一方、登録者の成績については導入講義の成績(100点満点の素点)を使用し、彼らのGPAは使用しなかった。その理由は、各教員が直接管理する登録者の学修データのみで除退予備軍を見出せるかどうかを検証するためである。
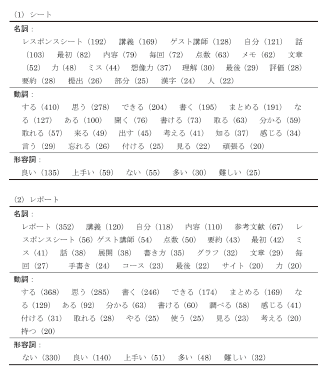
一方、彼らの文字情報については次のようにデータ化した。講義期間中提出された各シートの記述から名詞・動詞・形容詞をすべて数え上げ、それらの1回提出あたりの平均語彙数を計算した。そして、最終講義時のシートで書いた取り組み姿勢などに対する自己評価の記述から名詞・動詞・形容詞を数え上げ(注3)、その出現頻度から(次に解説する)6つの因子を抽出した。
なお、シート自己評価の自由記述では名詞467語、動詞284語、形容詞60語の計811語、レポート自己評価の自由記述では名詞493語、動詞284語、形容詞51語の計828語がそれぞれあった。このうち出現頻度20以上のものを図表1にまとめておいた。
(注2)これ以降の分析は、桃山学院大学共同研究プロジェクト「人文・社会科学におけるテキストマイニングの適用可能性」(19共270)における研究成果の一部である。
(注3)この作業はシートからテキストデータを作成し、フリーソフト「TTM」および「KHCoder」を使って品詞分解を行った。TTMを用いたテキストマイニングの手法については次の文献が詳しい。松村真宏・三浦麻子『人文・社会科学のためのテキストマイニング(改訂新版)』誠信書房、2014年。一方、KHCoderを用いたテキストマイニングの手法については次の文献が詳しい。末吉美喜『テキストマイニング入門ExcelとKHCoderで分かるデータ分析』オーム社、2019年。









